Discrete Distribution Networks
A Novel Generative Model with Simple Principles and Unique Properties
| Paper 📄 | Code 👨💻 | Talk 🎤 |
(Code/Talk Coming soon)
Contributions of this paper:
- We introduce a novel generative model, termed Discrete Distribution Networks (DDN), which demonstrates a more straightforward and streamlined principle and form.
- For training the DDN, we propose the Split-and-Prune optimization algorithm, and a range of practical techniques.
- We conduct preliminary experiments and analysis on the DDN, showcasing its intriguing properties and capabilities, such as zero-shot conditional generation and highly compact representations.
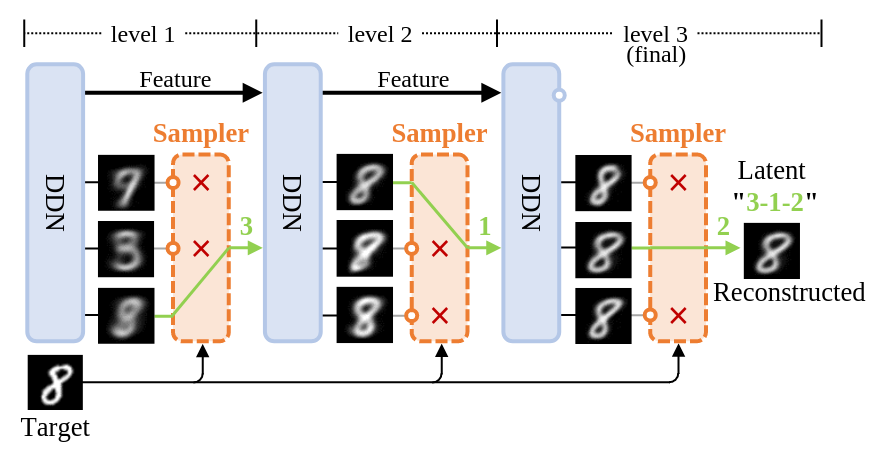
Left: Illustrates the process of image reconstruction and latent acquisition in DDN. Each layer of DDN outputs
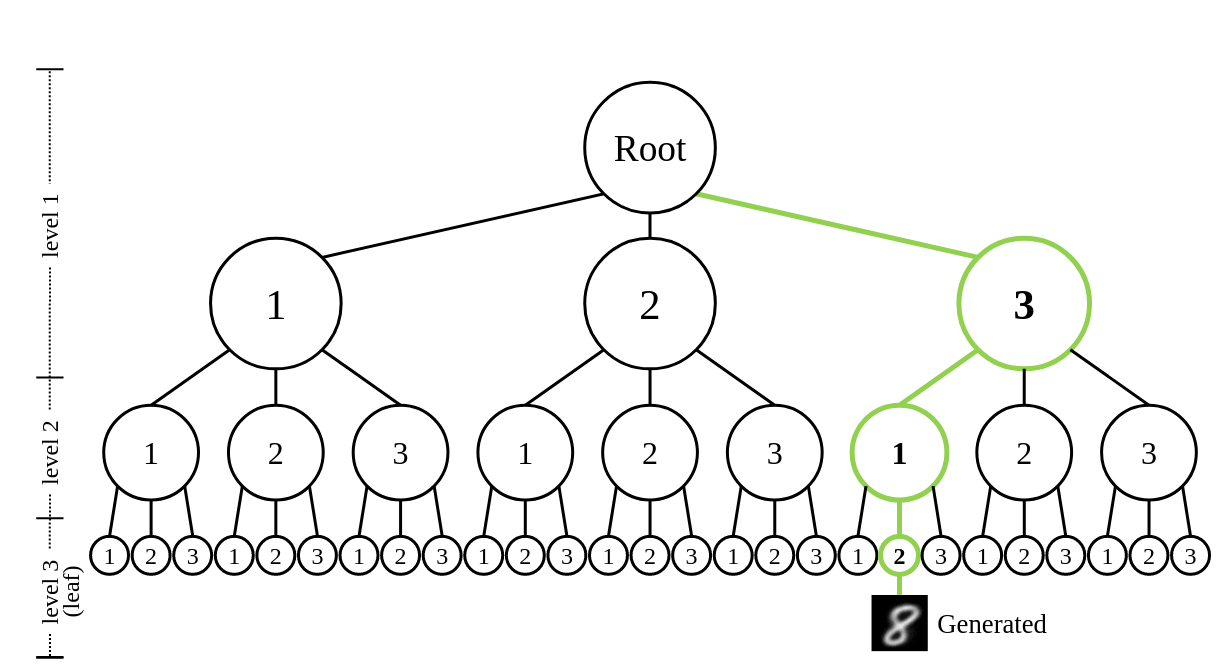
Right: Shows the tree-structured representation space of DDN's latent variables. Each sample can be mapped to a leaf node on this tree.
We introduce a novel generative model, the Discrete Distribution Networks (DDN), that approximates data distribution using hierarchical discrete distributions. We posit that since the features within a network inherently contain distributional information, liberating the network from a single output to concurrently generate multiple samples proves to be highly effective. Therefore, DDN fits the target distribution, including continuous ones, by generating multiple discrete sample points. To capture finer details of the target data, DDN selects the output that is closest to the Ground Truth (GT) from the coarse results generated in the first layer. This selected output is then fed back into the network as a condition for the second layer, thereby generating new outputs more similar to the GT. As the number of DDN layers increases, the representational space of the outputs expands exponentially, and the generated samples become increasingly similar to the GT. This hierarchical output pattern of discrete distributions endows DDN with two intriguing properties: highly compressed representation and more general zero-shot conditional generation. We demonstrate the efficacy of DDN and these intriguing properties through experiments on CIFAR-10 and FFHQ.

DDN enables zero-shot conditional generation. DDN also supports conditions in non-pixel domains, such as text-to-image with CLIP. Images enclosed in yellow borders serve as the ground truth. The abbreviations in the table header correspond to their respective tasks as follows: “SR” stands for Super-Resolution, with the following digit indicating the resolution of the condition. “ST” denotes Style Transfer, which computes Perceptual Losses with the condition.
Overview of Discrete Distribution Networks
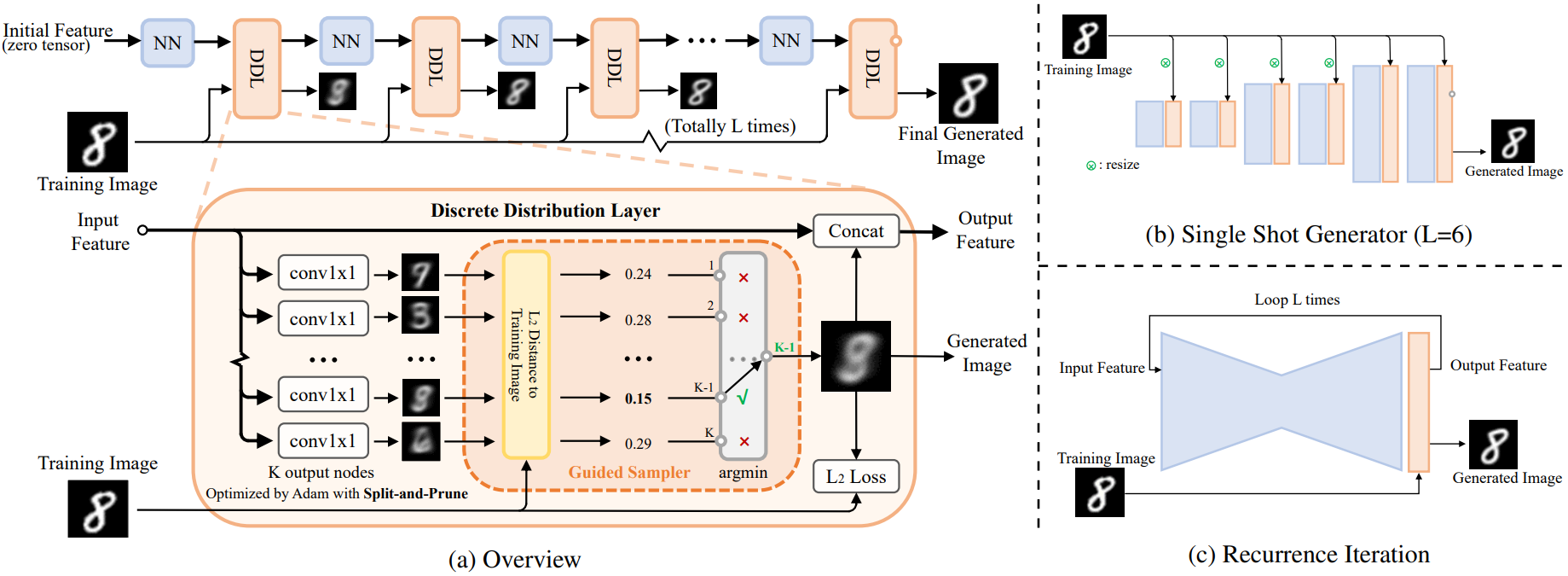
(a) The data flow during the training phase of DDN is shown at the top. As the network depth increases, the generated images become increasingly similar to the training images. Within each Discrete Distribution Layer (DDL),
Toy examples for two-dimensional data generation
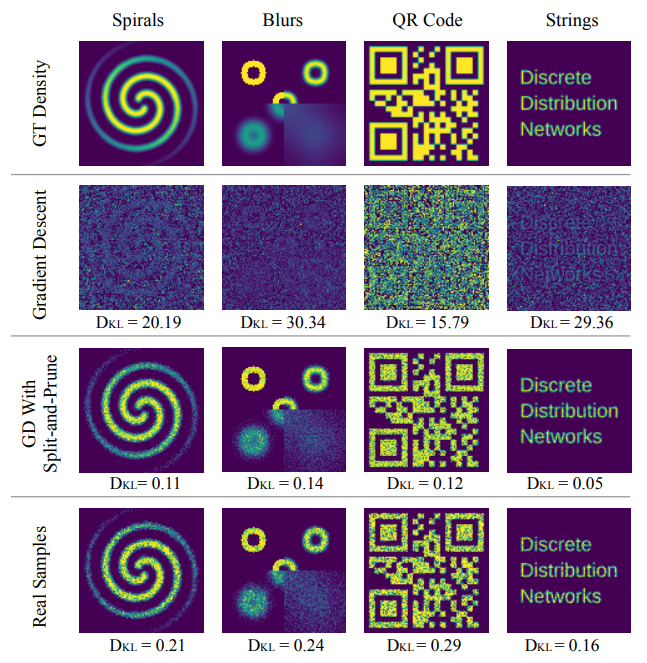
The numerical values at the bottom of each figure represent the Kullback-Leibler (KL) divergence. Due to phenomena such as “dead nodes” and “density shift”, the application of Gradient Descent alone fails to properly fit the Ground Truth (GT) density. However, by employing the Split-and-Prune strategy, the KL divergence is reduced to even lower than that of the Real Samples.

Zero-Shot Conditional Generation guided by CLIP
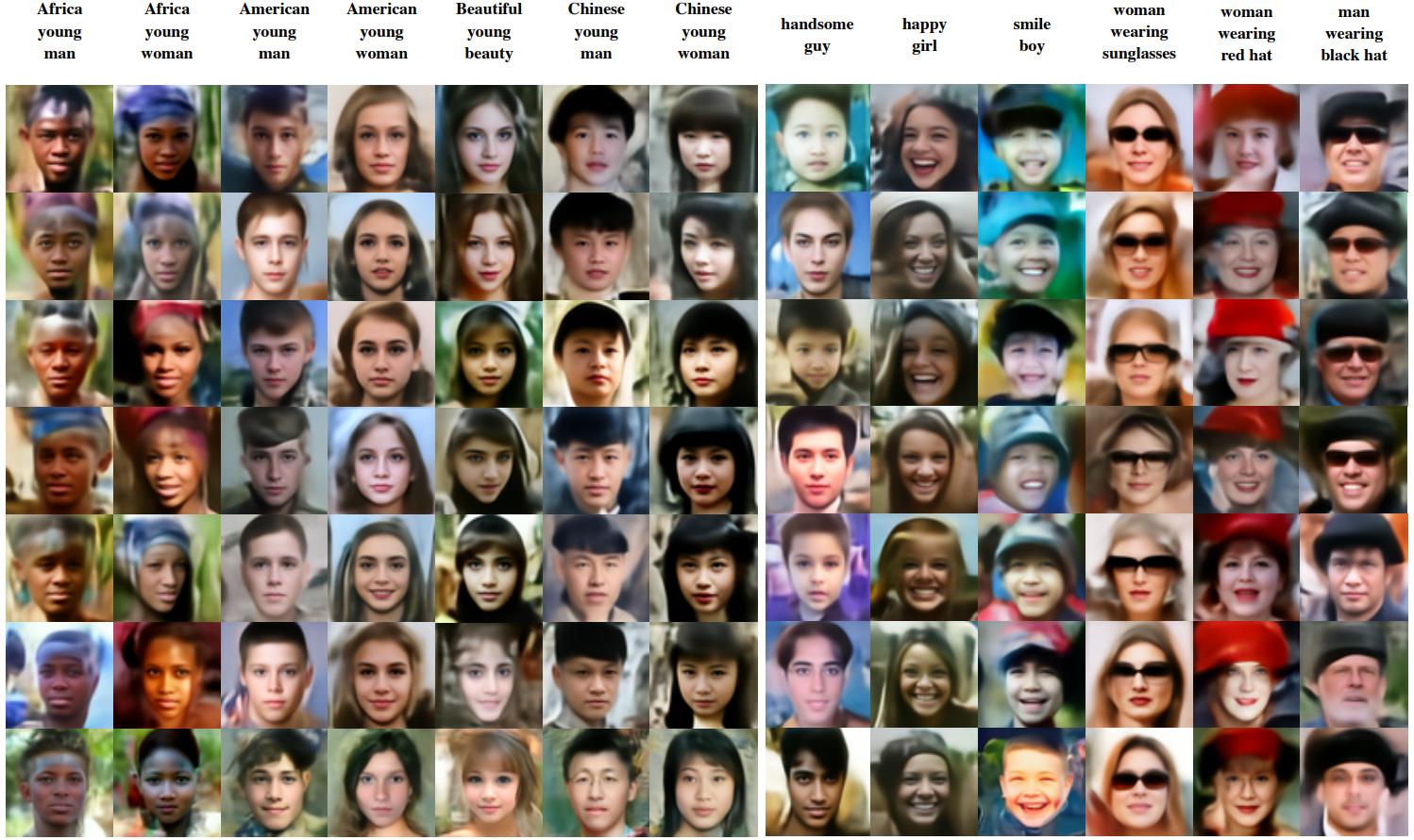
The text at the top is the guide text for that column.
Zero-Shot Conditional Generation with Multiple Conditions

The DDN balances the steering forces of CLIP and Inpainting according to their associated weights.
Conditional DDN performing coloring and edge-to-RGB tasks

Columns 4 and 5 display the generated results under the guidance of other images, where the produced image strives to adhere to the style of the guided image as closely as possible while ensuring compliance with the condition. The resolution of the generated images is 256x256.
Hierarchical Generation Visualization of DDN
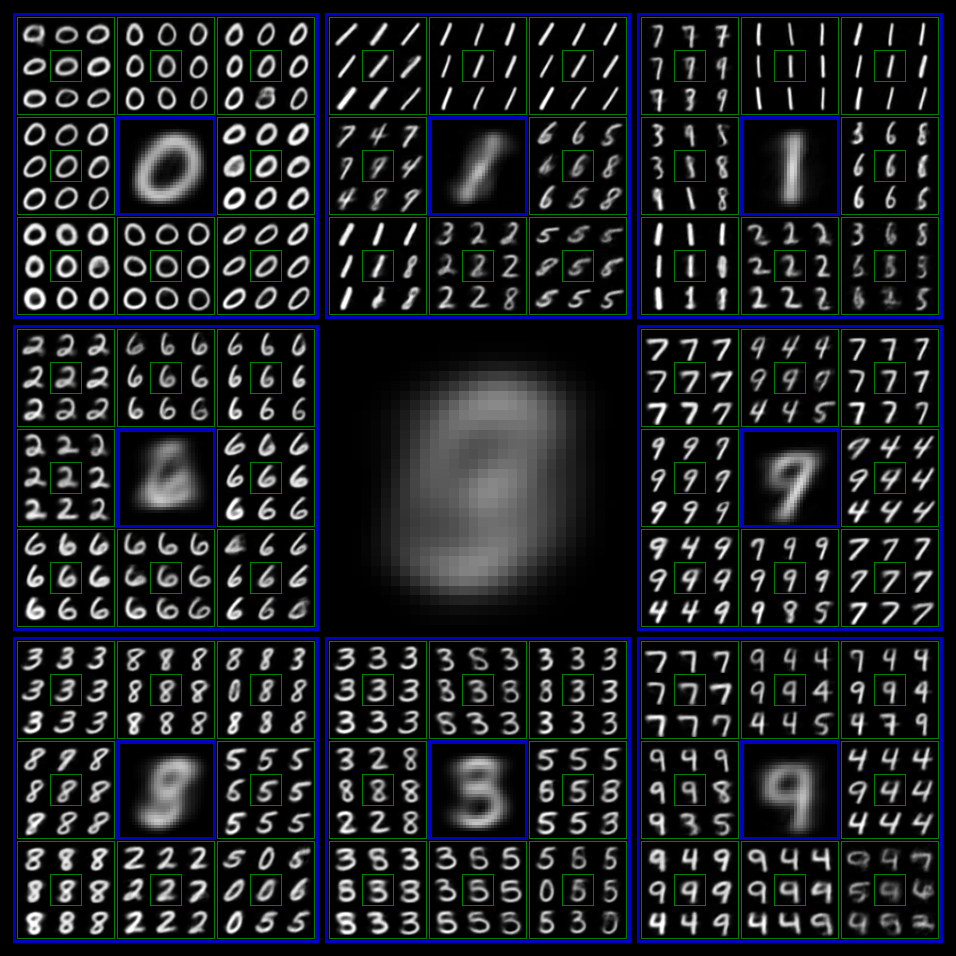
We trained a DDN with output level